Systems | Development | Analytics | API | Testing


April 2021


Why and when enterprises should care about Model Explainability
Machine learning models are often used for decision support—what products to recommend next, when an equipment is due for maintenance, and even predict whether a patient is at risk. The question is, do organizations know how these models arrive at their predictions and outcomes? As the application of ML becomes more widespread, there are instances where an answer to this question becomes essential. This is called model explainability.

Announcing Iguazio Version 3.0: Breaking the Silos for Faster Deployment
We’re delighted to announce the release of the Iguazio Data Science Platform version 3.0. Data Engineers and Data Scientists can now deploy their data pipelines and models to production faster than ever with features that break down silos between Data Scientists, Data Engineers and ML Engineers and give you more deployment options . The development experience has been improved, offering better visibility of the artifacts and greater freedom of choice to develop with your IDE of choice.

AI/ML without DataOps is just a pipe dream!
Let’s start with a real-world example from one of my past machine learning (ML) projects: We were building a customer churn model. “We urgently need an additional feature related to sentiment analysis of the customer support calls.” Creating the data pipeline to extract this dataset took about 4 months! Preparing, building, and scaling the Spark MLlib code took about 1.5-2 months!

Deep Learning with Nvidia GPUs in Cloudera Machine Learning
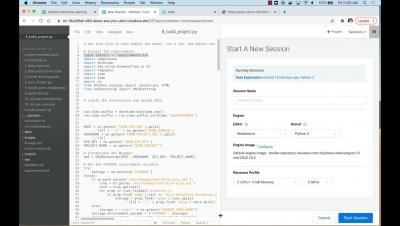
In our previous blog post in this series, we explored the benefits of using GPUs for data science workflows, and demonstrated how to set up sessions in Cloudera Machine Learning (CML) to access NVIDIA GPUs for accelerating Machine Learning Projects.
DataOps, AIOps, and MLOPs
Over the past several years, there has been an explosion of different terms related to the world of IT operations. Not long ago, it was standard practice to separate business functions from IT operations. But those days are a distant memory now, and for good reason.
10 Steps to Achieve Enterprise Machine Learning Success
You’ve probably heard it more than once: Machine learning (ML) can take your digital transformation to another level. It’s a pie-in-the-sky statement that sounds great, right? And while you’d be forgiven for thinking that it might sound too good to be true, operational ML is, in fact, achievable and sustainable. You can get the very kind of ML you need to increase revenue and lower costs. To help teams work smarter and do things faster.
A huge chunk of machine learning models are never operationalized-here's why
As organizations refocus and restrategize this year, machine learning projects seem to be on the top of IT priority lists. Innovation is more important than ever, and this has led to higher spending, increased hiring budgets, and a wider range of ML use cases. Despite this, organizations are facing challenges in actually deploying machine learning models at scale. A lot of models are never operationalized, or if they are, the process to production takes too long.
Enabling NVIDIA GPUs to accelerate model development in Cloudera Machine Learning
When working on complex, or rigorous enterprise machine learning projects, Data Scientists and Machine Learning Engineers experience various degrees of processing lag training models at scale. While model training on small data can typically take minutes, doing the same on large volumes of data can take hours or even weeks. To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deep learning workloads.

Building Automated ML Pipelines in Cloudera Machine Learning
Cloudera Machine Learning Overview

How to Tap into Higher-Level Abstraction, Efficiency & Automation to Simplify your AI/ML Journey
You’ve already figured out that your data science team cannot keep developing models on their laptops or a managed automated machine learning (AutoML) service and keep their models there. You want to put artificial intelligence (AI) and machine learning (ML) into action and solve real business problems.