Systems | Development | Analytics | API | Testing

Modern Software Development For Today's Systems & Applications

Kafka



UI-driven GitOps: Opening up Kafka without giving up governance
As Kafka evolves in your business, adopting best practices becomes a must. The GitOps methodology makes sure deployments match intended outcomes, anchored by a single source of truth. When integrating Apache Kafka with GitOps, many will think of Strimzi. Strimzi uses the Operator pattern for synchronization. This approach, whilst effective, primarily caters to Kubernetes-based Kafka resources (e.g. Topics). But this isn’t ideal.
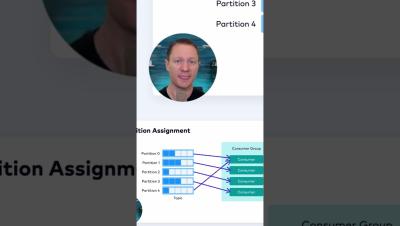
Kafka Consumer Partition Assignment
Learn how consumer partition assignment works in Apache Kafka.

Event-Driven Architecture (EDA) vs Request/Response (RR)
In this video, Adam Bellemare compares and contrasts Event-Driven and Request-Driven Architectures to give you a better idea of the tradeoffs and benefits involved with each. Many developers start in the synchronous request-response (RR) world, using REST and RPC to build inter-service communications. But tight service-to-service coupling, scalability, fan-out sensitivity, and data access issues can still remain.

Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
Confluent has published official Docker containers for many years. They are the basis for deploying a cluster in Kubernetes using Confluent for Kubernetes (CFK), and one of the underpinning technologies behind Confluent Cloud. For testing, containers are convenient for quickly spinning up a local cluster with all the components required, such as Confluent Schema Registry or Confluent Control Center.

Confluent Connectors | Fast, frictionless, and secure Apache Kafka integrations
Every company faces the perennial problem of data integration but often experiences data silos, data quality issues, and data loss from point-to-point, batch-based integrations. Connectors decouple data sources and sinks through Apache Kafka, simplifying your architecture while providing flexibility, resiliency, and reliability at a massive scale.

Confluent Announces Accelerate with Confluent, a Revamped and Services-Led Partner Program for System Integrators
Reimagined partner program will better enable SIs to drive growth and profitability, while helping customers realise their full potential with data streaming.

