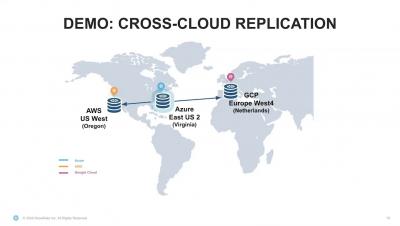
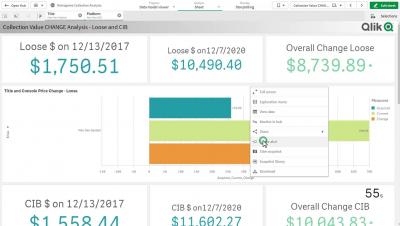
Join Optimization in Xplenty
During data analysis in SQL, one will often need to look at multiple tables and join them to get the desired results. Joining tables for analyzing data is a required skill for a data scientist or data engineer. Selecting the right join will optimize query performance.