New Connector: SAP Concur
Use our new SAP Concur integration for reliable, easy-to-use ELT for your financial analytics.


Use our new SAP Concur integration for reliable, easy-to-use ELT for your financial analytics.
Don’t make costly mistakes as your business strives to make better use of data.
Bring disparate spreadsheets into your centralized analytics destination.
Heroku is a cloud platform as a service (PaaS) for efficiently building, deploying, monitoring, and scaling applications. Originally created to work with the Ruby programming language, Heroku is now part of the Salesforce platform and supports languages such as Java, Node.js, PHP, Python, and Scala. While Heroku makes it easy to develop production-ready applications fast, one question remains: how can you integrate your Heroku app data with the rest of your data infrastructure and workflows?
Apache Spark is now widely used in many enterprises for building high-performance ETL and Machine Learning pipelines. If the users are already familiar with Python then PySpark provides a python API for using Apache Spark. When users work with PySpark they often use existing python and/or custom Python packages in their program to extend and complement Apache Spark’s functionality. Apache Spark provides several options to manage these dependencies.
Data science and big data are essential in today’s world of marketing. You’ve probably already seen multiple instances of both being used for advertising and sales purposes, but you may not realize just how useful they are. If you own a business, you need to know how to use data for your own marketing programs.
Cloudera released a lot of things around Apache NiFi recently! We just released Cloudera Flow Management (CFM) 2.1.1 that provides Apache NiFi on top of Cloudera Data Platform (CDP) 7.1.6. This major release provides the latest and greatest of Apache NiFi as it includes Apache NiFi 1.13.2 and additional improvements, bug fixes, components, etc. Cloudera also released CDP 7.2.9 on all three major cloud platforms, and it also brings Flow Management on DataHub with Apache NiFi 1.13.2 and more.
Your data now resides in the cloud, and you’ve chosen SaaS providers that use their own products (or drink their own champagne, as I like to say). Does that mean you’re getting the full value from your data? No. Chances are high your data is still siloed. This time, the culprits are your SaaS providers who collect and store your data, thus limiting the analytics you can perform on it.
New capabilities, including a custom-branded OEM option, enable product teams to blend data integration into their apps.
According to Statcounter, Apple’s iOS penetration in the global mobile scene is around 27%, which is more than considerable. However, this penetration is at almost 50% in markets such as Europe or North America which coincidentally, are those at the forefront of enacting strict data privacy policies. So when Apple announced new user data privacy regulations for app developers as part of its iOS 14.5 release, it was not too shocking.
As increasing aspects of business go digital, managing data has never been more crucial. According to Forbes, only one in four businesses has a "well-defined data management structure." If you’re looking to improve how you store, manage, and analyze your business data, it’s time to look at intelligent data integration tools. Fivetran is an ETL tool. ETL stands for "extract, transform, load".
The mission statement is so direct and uncomplicated. SU Queensland, a non-profit organization based in Australia, is all about “bringing hope to a young generation.” The realities of delivering on this charter, of course, are multi-dimensional and complex.
A radically new approach to data integration saves engineering time, allowing engineers and analysts to pursue higher-value activities.
Data pipeline orchestration is traditionally engineering-heavy. Use the modern data stack to free your engineers and analysts for higher-value projects.
Harnessing the power of big data is increasingly important not just for business intelligence (BI)—a descriptive model that reveals to enterprises the current state of their companies—but also for data analytics. Data analytics offer predictive models with insight into where a business might head under different scenarios. Your organization's data gives you the opportunity to collect dynamic business intelligence.
Cable and Satellite companies in the US have emerged from a decade of acquisitions, consolidation and shakeout and are beginning to assert themselves as full service providers in the communications and media space. With Comcast just announcing its new suite of cellphone plans this month, and Charter, Altice and Dish ramping up their offerings, the Big Three in wireless – AT&T, Verizon and T-Mobile/Sprint – are looking over their shoulders.
Cox Automotive is a large, global business. It’s part of Cox Enterprises, a media conglomerate with a strong position in the Fortune 500, and a leader in diversity. Cox also has a strong history of technological innovation, with its core cable television business serving as a leader in the growth and democratization of media over the last several decades.
Machine learning models are often used for decision support—what products to recommend next, when an equipment is due for maintenance, and even predict whether a patient is at risk. The question is, do organizations know how these models arrive at their predictions and outcomes? As the application of ML becomes more widespread, there are instances where an answer to this question becomes essential. This is called model explainability.
Originally developed by IBM, flat file databases have been around since the 1970s. Because these files store data in plain text format, most people use MS Excel to create them. It’s an easy-to-use system that allows for the quick sorting of results. This is because each line of plain text has just one record. Tabs, commas, or other delimiters separate multiple records. In this article, you’ll learn some tips for optimizing your flat file.
We’re delighted to announce the release of the Iguazio Data Science Platform version 3.0. Data Engineers and Data Scientists can now deploy their data pipelines and models to production faster than ever with features that break down silos between Data Scientists, Data Engineers and ML Engineers and give you more deployment options . The development experience has been improved, offering better visibility of the artifacts and greater freedom of choice to develop with your IDE of choice.
CDP is using Apache Ranger for data security management. If you wish to utilize Ranger to have a centralized security administration, HBase ACLs need to be migrated to policies. This can be done via the Ranger webUI, accessible from Cloudera Manager. But first, let’s take a quick overview of HBase method for access control.
A new Python package from Fivetran and Astronomer enables connector management in Airflow.
Many technologies of the last century are out of date now, but flat file databases are still very much in use today and likely will be for a long while yet. They’ve stood the test of time for over four decades and are still going strong for a variety of reasons.
Encryption of Data at Rest is a highly desirable or sometimes mandatory requirement for data platforms in a range of industry verticals including HealthCare, Financial & Government organizations. The capability increases security and protects sensitive data from various kinds of attack that could be internal or external to the platform.
Let’s start with a real-world example from one of my past machine learning (ML) projects: We were building a customer churn model. “We urgently need an additional feature related to sentiment analysis of the customer support calls.” Creating the data pipeline to extract this dataset took about 4 months! Preparing, building, and scaling the Spark MLlib code took about 1.5-2 months!
Customers interact with your business multiple times before reaching any goal. These repeated digital interactions are what make up the customer journey. Your customers’ overall experience across the different channels as they engage with your organization (websites, social media, email, etc.) make up the customer experience. Customer journey analytics refers to the process of analyzing the experience of customers across multiple touchpoints in the customer journey.
What can you do with data collected on Heroku PostgreSQL? How will you analyze it and integrate it? With Xplenty, of course! Xplenty lets you connect to a PostgreSQL database on Heroku, design a Dataflow via an intuitive user interface, aggregate the data, and even save it back to PostgreSQL on Heroku or other databases and cloud storage services.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Businesses are also looking to move to a scale-out storage model that provides dense storages along with reliability, scalability, and performance.
From five-engineer startup to 200-engineer unicorn, we’ve remained focused on one goal: making business data as accessible as electricity. Only a few years ago,
Soft skills can be almost as important as data engineering skills when you apply for a job. Soft skills can make the difference between stress and efficiency or being unsatisfied with your position and a raise. When data engineers and data scientists earn bachelor’s degrees, they usually take classes in topics like data warehousing, programming languages, machine learning, and data science.
Vermont Gas (VGS) is a leader in energy efficiency and innovation, offering a clean, safe, affordable choice for over 53,000 homes, businesses, and institutions in northwest Vermont. They pride themselves on providing timely, comprehensive service for all their customers, ensuring they have heat, hot water, and energy to get through the cold New England winter.
Like most of our customers, Cloudera’s internal operations rely heavily on data. For more than a decade, Cloudera has built internal tools and data analysis primarily on a single production CDH cluster. This cluster runs workloads for every department – from real-time user interfaces for Support to providing recommendations in the Cloudera Data Platform (CDP) Upgrade Advisor to analyzing our business and closing our books.
Adobe is a legendary Silicon Valley company. From the desktop publishing era of the 1980s, powered by the Adobe Postscript page description language, through the creation and marketing of Photoshop, Illustrator, and other creative power tools, the digital revolution is unthinkable without Adobe.
Although the title might sound like a collaboration of two music bands with really bad names, this blog is all about understanding how computer vision and machine learning can be used to improve safety and security in a harsh and dangerous environment of a construction site. The construction industry is one of the most dangerous industries according to the common stats from OSHA.
Ever since Salesforce acquired Heroku back in 2010, the two services have worked exceptionally well together. Businesses can use Heroku to build flexible and scalable applications while utilizing Salesforce to manage customer data and drive sales. And when you need to share data between these two platforms, there’s a dedicated add-on: Heroku Connect.
What is Streaming Analytics? Streaming Analytics is a type of data analysis that processes data streams for real-time analytics. It continuously processes data from multiple streams and performs simple calculations to complex event processing for delivering sophisticated use cases. The primary purpose is to present the most up-to-date operational events for the user to stay on top of the business needs and take action as changes happen in real-time.
Many people wonder if they should use BigQuery or Bigtable. While these two services have a number of similarities, including "Big" in their names, they support very different use cases in your big data ecosystem. At a high level, Bigtable is a NoSQL wide-column database. It's optimized for low latency, large numbers of reads and writes, and maintaining performance at scale.
Personally identifiable information (PII) and protected health information (PHI) are two types of sensitive data that fall under one or more data privacy regulations. HIPAA and GDPR are examples of the regulations that govern what organizations can and need to do with PII and PHI. When you work with large data sets, it can be challenging to maintain compliance with these regulations.
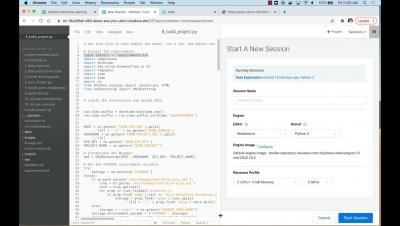
In our previous blog post in this series, we explored the benefits of using GPUs for data science workflows, and demonstrated how to set up sessions in Cloudera Machine Learning (CML) to access NVIDIA GPUs for accelerating Machine Learning Projects.
We've moved from desktop to SaaS, to a real UX focus. Now we're seeing new vendors that are analytics-first. They’re creating new applications that are challenging the established players. Historically, applications were transaction-first; you build your software thinking about your workflow or the transactions that you want people to do.
Custom code to connect with data APIs is quickly becoming a thing of the past.
Facebook recently announced that it will effectively discontinue Facebook Analytics on June 30, 2021. The announcement was not particularly informative and was limited to pointing out ways of retaining the tool’s users by means of diverting business to other features that Facebook already offers. However, the reasons behind this decision were not addressed by Facebook and it brings up the question of what this means for the industry.
With its low-code and no-code features, Xplenty brings the power of ETL and data integration to the masses. But even with Xplenty’s tremendously user-friendly interface, it’s possible that the transformations you design don’t work exactly as you intended—which means you need to debug and resolve the issue fast. Fortunately, there are multiple debugging options in Xplenty for exactly this reason.
The faster you can extract, transform, and load data from MongoDB, the better it is for your business processes and business intelligence systems. The problem is, most ETL solutions struggle to manage MongoDB’s dynamic schemas, NoSQL support, and JSON data types. That’s not the case with Xplenty – which was optimized for easy, no-fuss MongoDB integrations with ease: no custom code, no delays, no confusion.
According to IDG, when customers consider updating to the latest release of a product, they expect new features, enhanced security, and better performance, but increasingly want a more streamlined upgrade process. With each new release of CDP Private Cloud, this is exactly what we strive to deliver. Along with a host of new features and capabilities, we are improving the upgrade process to be as painless as possible.
Understandably, however, the many automation, AI and machine learning technologies that come with modern analytics solutions can sometimes be hard to keep up with. One area we get asked a lot about is ABM, which we offer with Yellowfin Signals, and what exact advantages it brings to the table for everyday analysis and insight generation.
The exponential adoption of IT technologies over the past several decades has had a profound impact on organizations of all sizes. Whether it is a small, medium, or large enterprise, the need to create web applications while managing an extensive set of data effectively is high on every CIO’s priority list. As a result, there has been an ongoing effort to implement better approaches to software development, data analysis, and data management.
As a developer, you're no stranger to your vast and varied data environment… Or are you? The tremendous amount of data your organization collects is stored in various sources and formats. You need a way to understand where and what data is, to be able to do what you need to do: build amazing event-driven applications.
Heroku is a powerful platform for application development. Users can build and deploy on the cloud, and you can effortlessly scale up once your app takes off. And behind every app, you'll find an equally powerful database: Heroku Postgres. If you're building Heroku apps, you'll find them to be a rich source of operational and customer data. Add in the right Business Intelligence (BI) tools, and you'll be able to derive insights about the inner workings of your organization.
Cloudera Data Engineering is a serverless service for Cloudera Data Platform (CDP) that allows you to submit jobs to auto-scaling virtual clusters. CDE enables you to spend more time on your applications, and less time on infrastructure. CDE allows you to create, manage, and schedule Apache Spark jobs without the overhead of creating and maintaining Spark clusters.
The blog “Migrating Apache NiFi Flows from HDF to CFM with Zero Downtime” detailed how many common NiFi dataflows can be easily migrated when the Hortonworks DataFlow and Cloudera Flow Management clusters are running side-by-side. But what if you lack the resources to run multiple NiFi clusters concurrently? Not a problem.
In this blog post, I’ll set up and run a couple of experiments to demonstrate the effects of different kinds of partition pruning in Spark.
Over the past several years, there has been an explosion of different terms related to the world of IT operations. Not long ago, it was standard practice to separate business functions from IT operations. But those days are a distant memory now, and for good reason.
Since the start of the pandemic nearly a year ago, there's been one word on the lips of every business leader, analyst, and investor around the world: cloud. COVID-19 fundamentally changed the way businesses operate. In response, organizations went all in on cloud, betting on the unmatched scale, speed, and security of SaaS applications to help them weather the storm. Nowhere was this shift more pronounced that in our own data and analytics industry.
Data integration has been around for decades in some form or fashion, as organizations are always looking for ways to combine their enterprise data and collect it in a centralized location. The most commonly used and dominant type of data integration is ETL (extract, transform, load). ETL first extracts data from one or more source systems, transforms it as necessary, and then loads it into a target warehouse or data lake.
What’s the fastest and easiest path towards powerful cloud-native analytics that are secure and cost-efficient? In our humble opinion, we believe that’s Cloudera Data Platform (CDP). And sure, we’re a little biased—but only because we’ve seen firsthand how CDP helps our customers realize the full benefits of public cloud.
You’ve probably heard it more than once: Machine learning (ML) can take your digital transformation to another level. It’s a pie-in-the-sky statement that sounds great, right? And while you’d be forgiven for thinking that it might sound too good to be true, operational ML is, in fact, achievable and sustainable. You can get the very kind of ML you need to increase revenue and lower costs. To help teams work smarter and do things faster.
As organizations refocus and restrategize this year, machine learning projects seem to be on the top of IT priority lists. Innovation is more important than ever, and this has led to higher spending, increased hiring budgets, and a wider range of ML use cases. Despite this, organizations are facing challenges in actually deploying machine learning models at scale. A lot of models are never operationalized, or if they are, the process to production takes too long.
Trying to integrate your marketing data sources? Here are the fundamental differences between Fivetran and Supermetrics as marketing ETL tools.
When it comes to data storage, there is almost as much diversity in the types of databases as there is in the data that they contain. Designing and implementing a strong enterprise data strategy means that you need to be aware of the different databases and how you might best apply them within your organization. In IT, the term "flat file" means something very different from the heavy-duty steel construction file cabinets that you might buy from Safco.
The United States Veterans Administration (VA) over the last decade underwent a massive enterprise-wide IT transformation, eliminating its fragmented shadow IT and adopting a centralized system capable of supporting the agency’s 400,000 employees and more effectively utilizing its $240 billion-plus annual budget. The result: A more reliable and modern IT environment that improves access, availability, and user experience -ultimately supporting the VA mission more effectively.
One of the changes that we've seen happening in the analyst space recently is a huge shift in thinking. Gartner in particular is now talking about augmented consumers and multi-experience analytics. To me, this is really interesting because they’re talking about the business user and how they want to work and consume data. In the past it was all about the data analyst, but focusing on users opens up an entirely new level of thinking.
From the Wright Brothers and Ada Lovelace, to Elon Musk and Steve Jobs, when we consider who is behind the most celebrated innovations and industry transformations, we often think about individual bright thinkers and disruptors. However, over the years, studies have shown that the greatest potential lies in the “power of many," fostered by a shift in how new generations work.
When working on complex, or rigorous enterprise machine learning projects, Data Scientists and Machine Learning Engineers experience various degrees of processing lag training models at scale. While model training on small data can typically take minutes, doing the same on large volumes of data can take hours or even weeks. To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deep learning workloads.
Companies with B2C & B2B channels have unique challenges with intelligence and automation, best served by the Modern Data Stack.
This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The first blog introduced a mock vehicle manufacturing company, The Electric Car Company (ECC) and focused on Data Collection. The second blog dealt with creating and managing Data Enrichment pipelines. The third video in the series highlighted Reporting and Data Visualization.
Enterprise data warehouse platform owners face a number of common challenges. In this article, we look at seven challenges, explore the impacts to platform and business owners and highlight how a modern data warehouse can address them.
Many organizations are working to become more data-driven – increasing data use and leveraging data insights to improve decision-making, solve their most challenging problems and improve revenue and profitability. A February 2020 IDC survey showed a direct correlation between quality decision-making and strong data-to-insight capabilities; 57 percent of organizations with the best data analytics pipelines received the highest decision-making score.
Use these five strategies to align key resources and ensure that insights guide your decision-making.
Data Scientists can drive innovation and growth, but you need to put in place the right foundation to fully unlock business value.
As a startup in the fintech sector, Branch helps redefine the future of work by building innovative, simple-to-use tech solutions. We’re an employer payments platform, helping businesses provide faster pay and fee-free digital banking to their employees. As head of the Behavioral and Data Science team, I was tapped last year to build out Branch’s team and data platform. I brought my enthusiasm for Google Cloud and its easy-to-use solutions to the first day on the job.
In 2011, Pope John Paul II was beatified, Prince William married Kate Middleton, "Game of Thrones" premiered, and Xplenty was born. On a quiet sycamore tree-lined street in Tel Aviv, Israel, breathing distance from Kiryat Sefer Park, the then-startup had just launched a game-changing Extract, Transform, Load (ETL) tool to process, transform, and move data at speed and generate big data analytics at scale. It would become the most advanced data pipeline platform on the planet.
With 9.5, we've focused on providing new capabilities and enhancements for everyone involved in the data to design workflow - analysts, developers, users - that streamline processes, introduce functional improvements and enrich the analytic experience for all. For the full list of updates, please read the release notes and check out our release highlights video below to see some of these new enhancements in action for yourself.
Our obsessive focus on customer success is at the heart of all things we do.
Cloud Dataprep by Trifacta is Google Cloud’s intelligent data service for visually exploring, cleaning, and preparing structured and unstructured data for analytics and machine learning. Due to its serverless architecture, Dataprep does not need any infrastructure to deploy or manage, and is fully scalable.
As companies grow and become more data-dependent, data engineers find themselves in huge demand. Employers are snapping up all the best data engineering talent they can find, and some businesses have invested in fast-track professional development paths for DBAs and other more junior data positions. But here’s the thing — data engineers work best when they’re part of a balanced team, just like every other professional. Some organizations overlook this point.
Insurance carriers have a unique opportunity: They have access to powerful technologies and a wealth of information that can help them to better understand their customers and provide an enhanced customer experience.
Reverse ETL is an emerging piece of the modern data stack that enables you to productionize your analytics.
Reports and records. Sales sheets and spreadsheets. Files and financials. Your team has more big data than you can comprehend spread across multiple data sources in more locations than a James Bond movie. Isn't it time you kept this data somewhere safe? Moving data to a data warehouse like Snowflake is like keeping thousands of books in a library or a trove of treasure in an underground vault. Big data, your most prized asset, will be safe and snug.
You’ve already figured out that your data science team cannot keep developing models on their laptops or a managed automated machine learning (AutoML) service and keep their models there. You want to put artificial intelligence (AI) and machine learning (ML) into action and solve real business problems.
Today, technology drives organizations. We rely on it, which is why a misstep in selecting technology partners and their SaaS solutions can impact an organization in regrettable ways. It can impede your ability to scale in a graceful manner. It can slow down your journey of automation. It can even introduce risk related to compliance or security, depending on the solution. Whenever you decide to buy, a proper assessment of any SaaS provider is crucial.
To accelerate business value and enable a first-class cloud experience for our customers, we continue to shift the focus from passive to active BI with new innovations on the horizon.
ETL, long a mainstay of data integration, is labor-intensive, brittle, complex — and ripe to be supplanted by ELT.
MongoDB is a popular non-relational (a.k.a NoSQL) database. It is document-oriented and distributed in nature. MongoDB is known to be highly scalable and flexible. In this post, we'll demonstrate how you can utilize MongoDB in your ETL pipelines with Xplenty. To start with, let us briefly discuss why and when you'd want to use MongoDB over other relational databases.
Cloudera is being acknowledged by CRN®, a brand of The Channel Company, in its 2021 Partner Program Guide. This annual guide provides a conclusive list of the most distinguished partner programs from leading technology companies that provide products and services through the IT Channel. The 5-Star rating is awarded to an exclusive group of companies that offer solution providers the best of the best, going above and beyond in their partner programs.
Whilst not as well-known as other tech hotspots, many technology companies have been successfully launched and grown up here in Australia, with great economic and legal conditions, access to a talented and diversified skill-base, and a culture of innovation and adaptability acting as some key - and growing - attractions for leaders. So, why Australia? Sun, sand, surf, etc.
One of the most leading questions we often receive is, “How does ClearML Compare to..”. I am sure this is the same for any Open Source product. People always want to find the best. The sad truth is, of course, there usually is no “right answer”. What one person needs, another may not. I am sure that, whichever language you speak natively, there is some saying. In English it would be “one mans rubbish, is another mans gold”.
By centralizing processes and reimagining the role of its analysts, Calix’s data team found that it could deliver more value faster.
BigQuery is Google's flagship data analytics offering, enabling companies of all sizes to execute analytical workloads. To get the most out of BigQuery, it’s important to understand and monitor your workloads to keep your applications running reliably. Luckily, with Google’s INFORMATION_SCHEMA views, monitoring your organization’s use at scale has never been easier. Today, we’ll walk through how to monitor your BigQuery reservation and optimize performance.
Some of the most forward-operational elements of the United States federal government are making strides in leveraging data through hybrid cloud environments—and they’re constantly evaluating progress and recalibrating their approaches along the way. At agencies including the Army and the State Department, work is well underway to find ways of employing emerging technologies that build on cloud services and data optimization to realize new levels of effectiveness.
Chances are, your data contains information about geographic locations in some form, whether it’s addresses, postal codes, GPS coordinates, or regions that are meaningful to your business. Are you putting this data to work to understand your key metrics from every angle? In the past, you might’ve needed specialized Geographic Information System (GIS) software, but today, these capabilities are built into Google BigQuery.
A quick and easy way to speed up small queries in BigQuery (such as to populate interactive applications or dashboards) is to use BI Engine. The New York Times, for example, uses the SQL interface to BI Engine to speed up their Data Reporting Engine. To Illustrate, I’ll use three representative queries on tables between 100 MB and 3 GB — tables that are typically considered smallish by BigQuery standards.
Those who use data wisely have competitive advantages and more profits. As a result, companies are increasing their focus on improving their data literacy. For example, the importance of data has led companies like AppNexus1 and Chevron2 to conduct internal data science competitions to identify and hone analytical talent. But, as noted in the kickoff blog post to our series on data-driven organizations, merely having data does not ensure you have a useful interpretation of that data.
Working in the engineering field means navigating a variety of needs. Those range from meeting various local and national regulatory statutes, to measuring and monitoring delivery of essential outputs like drinking water and power supply, to understanding the data surrounding regional operations on both the supply and demand side. Organizations that serve this market operate behind the scenes, yet impact our daily life in the United States.