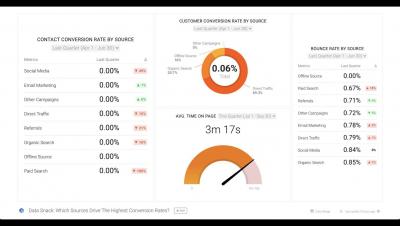
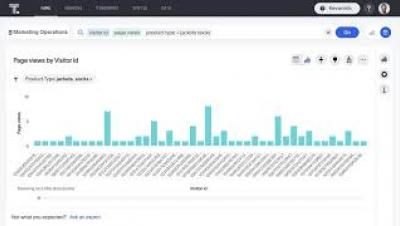
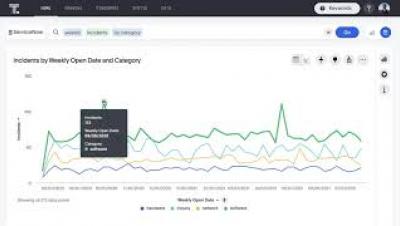
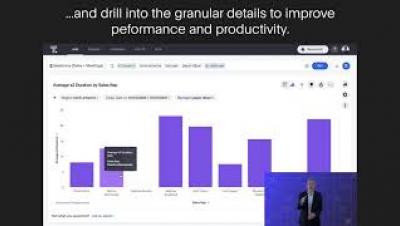
Introducing the Industry's Most Secure Cloud Data Integration Platform
Fivetran Business Critical meets the needs of enterprises with extremely sensitive data and strict compliance requirements.


Fivetran Business Critical meets the needs of enterprises with extremely sensitive data and strict compliance requirements.
While many businesses struggled to keep pace with the changing economics of a global pandemic, the real estate industry was booming. The housing market reached record-breaking heights last month, with median existing-price homes rising 17.2% over the prior year. This increase in the average cost of a house was compounded by accelerated closing times, as the average house sold in 18 days, a record low.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy data warehouses into Cloudera Data Platform.
The era of manual data management and governance is rapidly coming to a close. The size of the trove of data at nearly every company has become so enormous that it cannot be maintained using manual cleaning, cataloging, governance and search methods. The release of Lumada Data Catalog 6.1 breaks new ground in automating data management, cleaning and governance processes, making it easier to find data and grant access to those who need it.
Corporate finance must change. Across industries, an organization’s Finance team should shed light on what’s happening today with revenue and other financial indicators, while also predicting what the future may hold. And they must do the same for the entire organization. Until recently, it would have been impossible to meet these expectations. Excel-driven forecasting requires herculean efforts to wrangle data and report numbers by the end of each quarter.
Our rapid growth trajectory continues as Fivetran is recognized for completeness of vision and ability to execute.
CPG executives invest billions of dollars in trade and consumer promotion investments every year, spending as much as 15-20% of their total annual revenues on these initiatives. However, studies show that less than 72% of these promotions don’t break even and 59% of them fail. Despite these troubling statistics, most CPG organizations continue to design and execute essentially the same promotions year after year with negligible hope of obtaining sustained ROI.
Find out how everyone at your organization can contribute to healthier data for an accurate view of customers in 3 easy steps: www.talend.com/solutions/customer-360/
Learn how to design normalized schemas that make life easier for analysts and data engineers.
In the final episode of season two of The Data Chief podcast, we talk with authors of four must-read books for data and analytics leaders — two new and two time-tested. As you invest in your continuous learning, here is the full round up of the latest top books I recommend for today’s data and analytics leaders.
French multinational automotive manufacturer Renault Group has been investing in Industry 4.0 since the early days. A primary objective of this transformation has been to leverage manufacturing and industrial equipment data through a robust and scalable platform. Renault designed an industrial data acquisition layer and connected it to Google Cloud, using optimized big data products and services that together form Renault's Industrial Data Platform.
Last week, we shared information on BigQuery APIs and how to use them, along with another blog on workload management best practices. This blog focuses on effectively monitoring BigQuery usage and related metrics to operationalize workload management we discussed so far.
Apache Ozone is a scalable distributed object store that can efficiently manage billions of small and large files. Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. The object store is readily available alongside HDFS in CDP (Cloudera Data Platform) Private Cloud Base 7.1.3+.
In our modern world, accelerating the process of extracting insights from data is a complex challenge. Exacerbating this task are colossal data volumes, the expansion and use of multiple cloud platforms, and the increasing demands for self-service in a way that maintains compliance. Enterprises attempting to tackle the problem encounter various forms of friction everywhere they turn.
During the process of turning data into insights, the most compelling data often comes with an added responsibility—the need to protect the people whose lives are caught up in that data. Plenty of data sets include sensitive information, and it’s the duty of every organization, down to each individual, to ensure that sensitive information is handled appropriately.
COVID-19 vaccines were developed in record time. One of the main reasons for the accelerated development was the quick exchange of data between academia, healthcare institutions, government agencies, and nonprofit entities. “COVID research is a great example of where sharing data and having large quantities of data to analyze would be beneficial to us all,” said Renee Dvir, solutions engineering manager at Cloudera.
According to Harvard Business Review, South Korea is one of the leading countries in the world for technology innovation, and it’s among the top producers of new data. Technology is so ingrained in the national identity that it launched a “Digital New Deal” to lay the foundation for a digital economy that will facilitate growth and innovation, according to PR Newswire.
How to use a cloud data warehouse to achieve HIPPA compliance, reduce risk and offload some of the operational burden. How do you balance an accessible data warehouse with data protection and HIPAA Compliance? To get the most value from your data, it should be available to everyone in your organization who can benefit from the data analysis, insights and value it holds.
Enabling customers and users to quickly find the value within a product is critical for many organizations and at the heart of being a product manager. The approach to driving user growth involves a growth mindset, combining qualitative and quantitative research methods, and driving impactful solutions.
In 2020, the gaming market generated over 177 billion dollars, marking an astounding 23% growth from 2019. While it may be incredible how much revenue the industry develops, what’s more impressive is the massive amount of data generated by today’s games. There are more than 2 billion gamers globally, generating over 50 terabytes of data each day.
There is an urgent need for banks to be nimble and adaptable in the thick of a multitude of industry challenges, ranging from the maze of regulatory compliance, sophisticated criminal activities, rising customer expectations and competition from traditional banks and new digital entrants. As banks find their bearings in this landscape, what appear to be insurmountable odds are in fact opportunities for growth and competitive differentiation.
In the first part of this series , I outlined the prerequisites for a modern Enterprise Data Platform to enable complex data product strategies that address the needs of multiple target segments and deliver strong profit margins as the data product portfolio expands in scope and complexity: With this article, I will dive into the specific capabilities of the Cloudera Data Platform (CDP) that has helped organizations to meet the aforementioned prerequisite capabilities and fulfill a successful data prod
Over the last year, perhaps unsurprisingly, increasing numbers of companies have made the jump to the cloud. It’s become a necessary move for so many businesses. But, as I discussed with Joe DosSantos on the latest episode of Data Brilliant – the rewards are abundant, but the journey is not always straight forward.
Interested in transformations? Avoid these pitfalls and embrace these best practices to get the most out of data transformation.
In the most recent season of BigQuery Spotlight, we discussed key concepts like the BigQuery Resource hierarchy, query processing, and the reservation model. This blog focuses on extending those concepts to operationalize workload management for various scenarios.
So far in this series, we’ve been focused on generic concepts and console-based workflows. However, when you’re working with huge amounts of data or surfacing information to lots of different stakeholders, leveraging BigQuery programmatically becomes essential. In today’s post, we’re going to take a tour of BigQuery’s API landscape - so you can better understand what each API does and what types of workflows you can automate with it.
If the COVID-19 pandemic has taught us anything, it is that speed and intelligence are of the essence when it comes to making business decisions. Organizations must find ways of keeping ahead of competitors and disruptions by continually leveraging data to make smart decisions. The problem? Data may be everywhere, but it’s not always available in a form that businesses can use to generate analytics in real time.
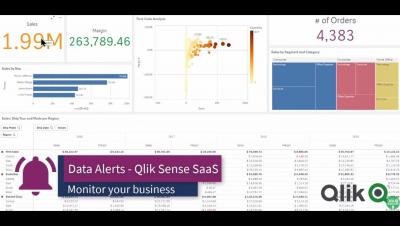
Businesses are flooded with constantly changing thresholds brought on by seasonality, special promotions and changes in consumer habits. Manual monitoring with static thresholds can’t account for events that do not occur in a regularly timed pattern. That’s why historical context of influencing events is critical in preventing false positives, wasted resources and disappointed customers.
As enterprises seek to accelerate the process of getting insights from their data, they face numerous sources of friction. Data sprawl across silos, diverse formats, the explosion of data volumes, and the fact that data is spread across many data centers and clouds and processed by many disparate tools, all act to slow the progress.
In digital transformation projects, it’s easy to imagine the benefits of cloud, hybrid, artificial intelligence (AI), and machine learning (ML) models. The hard part is to turn aspiration into reality by creating an organization that is truly data-driven.
The manufacturing industry, like any other industry, is not immune to data challenges. Sourcing data, wrangling it and ensuring it’s being used in a governed, standardized way are not uncommon problems. Particularly in manufacturing, issues surface with inventory management, within the supply chain and with logistics.
Fivetran dbt Packages accelerate analytics with off-the-shelf SQL for data modeling.
When we announced the GA of Cloudera Data Engineering back in September of last year, a key vision we had was to simplify the automation of data transformation pipelines at scale. By leveraging Spark on Kubernetes as the foundation along with a first class job management API many of our customers have been able to quickly deploy, monitor and manage the life cycle of their spark jobs with ease. In addition, we allowed users to automate their jobs based on a time-based schedule.
At Airflow Summit 2021, Unravel’s co-founder and CTO, Shivnath Babu, led a talk titled Data Pipeline HealthCheck for Correctness, Performance & Cost Efficiency. This story, along with the slides and videos included in it, come from the presentation.
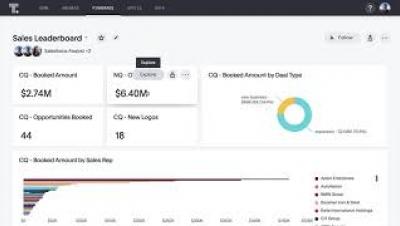
How does data enable Business Value Acceleration – and where’s the big opportunity for CXOs? Click here here to learn more: https://www.qlik.com/us/executive-insights
For more than 20 years, OpenTable has connected foodies and novice diners with the restaurants they love. But how does its technology work on the back end? To make a long story short: data. Beyond the app and website, OpenTable provides restaurants with software that manages their floor plans, phone reservations, walk-ins, shift scheduling, turn times, and more.
Are you ready to turbo-charge your data flows on the cloud for maximum speed and efficiency? We are excited to announce the general availability of Cloudera DataFlow for the Public Cloud (CDF-PC) – a brand new experience on the Cloudera Data Platform (CDP) to address some of the key operational and monitoring challenges of standard Apache NiFi clusters that are overloaded with high-performant flows.
We just announced Cloudera DataFlow for the Public Cloud (CDF-PC), the first cloud-native runtime for Apache NiFi data flows. CDF-PC enables Apache NiFi users to run their existing data flows on a managed, auto-scaling platform with a streamlined way to deploy NiFi data flows and a central monitoring dashboard making it easier than ever before to operate NiFi data flows at scale in the public cloud.
Migros is the largest retailer in Turkey, with more than 2500 outlets selling fresh produce and groceries to millions of people. To maintain high-quality operations, the company depends on fresh, accurate data. And to ensure high data quality, Migros depends on Talend. The sheer volume of data managed by Migros is astonishing. The company’s data warehouse currently holds more than 200 terabytes, and Migros is running more than 7,000 ETL (extract, transform, load) jobs every day.
Every enterprise is trying to collect and analyze data to get better insights into their business. Whether it is consuming log files, sensor metrics, and other unstructured data, most enterprises manage and deliver data to the data lake and leverage various applications like ETL tools, search engines, and databases for analysis. This whole architecture made a lot of sense when there was a consistent and predictable flow of data to process.
Hopefully you’ve been following along with our BigQuery Admin series and are well on your way to getting ramped up with BigQuery. Now that you’re equipped with the fundamentals, let's talk about something that’s relevant for all data professionals - data governance.
In my previous blog post, I shared examples of how data provides the foundation for a modern organization to understand and exceed customers’ expectations. However, the important role data occupies extends beyond customer experience and revenue, as it becomes increasingly central in optimizing internal processes for the long-term growth of an organization.
The arrival of more and more data in all segments of the enterprise started out as an embarrassment of riches, but quickly transformed into something close to a nightmare of dark data. However, a raft of new technologies and the processes embodied in DataOps are charting a path forward in which a much higher percentage of data becomes useful. The challenge most companies face is how to manage and get access to all the data flooding in from all directions.
In this episode of Data+AI Battlescars, Sandeep Uttamchandani, Unravel Data’s CDO, speaks with Samir Boualla, CDO at ING Bank France, one of the largest banks in the world. They cover his battlescars in Driving Data Governance Across Business Teams and Building Data Products. At ING Bank France, Samir is the Chief Data Officer. He’s responsible for several teams that govern, develop, and manage data infrastructure and data assets to deliver value to the business.
We all know data is the new oil. Both data and oil are valuable resources and share a common quality; if unprocessed they cannot be used. Data and oil have to be broken down and built up again to create true value for the business. There is, however, one key difference. Whereas oil is tangible, data is not. This means that the flow of low-quality oil is traceable and will be noticed in the production process. But, what happens if there is a bad data flow in your organization?
Should your data team focus on business problems and use cases, or expand into more complex areas like predictive analytics?
Not sure whether SQL or GUI transformations are better for your business? Here are the pros and cons of each approach.
We are roughly a decade removed from the beginnings of the modern machine learning (ML) platform, inspired largely by the growing ecosystem of open-source Python-based technologies for data scientists. It’s a good time for us to reflect back upon the progress that has been made, highlight the major problems enterprises have with existing ML platforms, and discuss what the next generation of platforms will be like.
At Talend, we believe achieving healthier data is essential for business success. Safeguarding private data and staying in compliance with global regulations leads to healthier data by significantly decreasing risk – reducing the potential of having to pay dizzying fines or suffering a data breach that destroys customer relationships and trust.
Once upon an IT time, everything was a “point product,” a specific application designed to do a single job inside a desktop PC, server, storage array, network, or mobile device. Point solutions are still used every day in many enterprise systems, but as IT continues to evolve, the platform approach beats point solutions in almost every use case. A few years ago, there were several choices of data deduplication apps for storage, and now, it’s a standard function in every system.
Snowflake is happy to announce the availability of the Object Tagging feature in public preview today! This feature makes it easier for enterprises to know and control their data by applying business context, such as tags that identify data objects as sensitive, PII, or belonging to a cost center. Object Tagging broadens Snowflake’s native data governance capabilities by adding to existing governance capabilities such as Snowflake’s Dynamic Data Masking and Row Access Policies.
An effective SEO strategy requires you to create unique and SEO-friendly articles and blog posts consistently. This is the only way for you to make your blog seem relevant in the eyes of the search engines. But creating unique content is not always easy. Every content writer has to face at least some degree of writer’s block at some point in their writing journey. If you are going through the same problem and you are feeling stuck, then using paraphrasing tools can be quite helpful for you.
It is becoming increasingly difficult to standardize taste. The myriad culinary preferences and gastric demands of the American population are reflected in the $997B valuation of the U.S. packaged food market in 2020. There has also been a push in recent years to augment trips to the grocery store with at-home meal kits and food delivery services, a trend further accelerated by the onset of quarantine restrictions.
Many a time, the choosing of a product analytics vendor can be quite an ordeal because there is no one-size-fits-all solution. The technical factors such as tech stack compatibility and integrations with the product have to be balanced with the financial health of the business. You need to find the sweet spot between where you need to go and how much money you actually have to get there.
Everyone knows that more and more data is moving to the cloud. According to the latest research, 94% of all enterprises use cloud services and 48% of businesses store classified and important data in the cloud. While the cloud is ubiquitous, in practice it consists of data infrastructures in various locations around the world. The question of where the cloud data infrastructure storing your specific data is located is becoming increasingly important.
With the release of CDP Private Cloud (PvC) Base 7.1.7, you can look forward to new features, enhanced security, and better platform performance to help your business drive faster insights and value. We understand that migrating your data platform to the latest version can be an intricate task, and at Cloudera we’ve worked hard to simplify this process for all our customers.
As businesses look to scale-out storage, they need a storage layer that is performant, reliable and scalable. With Apache Ozone on the Cloudera Data Platform (CDP), they can implement a scale-out model and build out their next generation storage architecture without sacrificing security, governance and lineage. CDP integrates its existing Shared Data Experience (SDX) with Ozone for an easy transition, so you can begin utilizing object storage on-prem.
Snowflake connected with David Coluccio from S&P Global Market Intelligence at the Snowflake Data Cloud Tour to hear how the company is using the Snowflake Data Cloud to curate massive amounts of data and provide seamless access for its clients. S&P Global’s foundation is rooted in providing essential insights to make more-informed decisions.
Amid the rapid pace of change felt by organizations this year, it’s no surprise that digital transformation projects have been high on the agenda for CIOs across the globe. To achieve both their organizational and transformation goals and become digitally agile as a result, CIOs are often tasked with creating the conditions needed to enable an intelligent and flexible digital core.
Building on the announcements made at this year’s Summit, Snowflake has released a number of new enhancements, especially in the areas of data programmability, global governance, and data sharing. Read on to learn more. For additional details and to see some of these new capabilities in action, be sure to check out the on-demand sessions from Summit.
Everyone wants to manage their data, and if it’s a feature store, even better! But for optimal data management, we must first discuss lightweight zero upfront setup costs and maximizing utility with ClearML-data. ClearML-data mimics the light weightiness of git for data (who doesn’t know git?) and gives it a spin. It is an open-source dataset management tool which is extremely efficient and conveys how we view DataOps and its distinction from git-like solutions, including.
For the newest instalment in our series of interviews asking leading technology specialists about their achievements in their field, we’ve welcomed Mark Kerzner, software developer and thought leader in cybersecurity training who is also the VP at training solutions company, Elephant Scale. His company has taught tens of thousands of students at dozens of leading companies. Elephant Scale started by publishing a book called ‘Hadoop Illuminated‘.
Today’s organizations face rising customer expectations in a fragmented marketplace amidst stiff competition. This landscape is one that presents opportunities for a modern data-driven organization to thrive. At the nucleus of such an organization is the practice of accelerating time to insights, using data to make better business decisions at all levels and roles.
“The most difficult thing is finding out why your job is failing, which parameters to change. Most of the time, it’s OOM errors…” Jagat Singh, Quora Spark has become one of the most important tools for processing data – especially non-relational data – and deriving value from it. And Spark serves as a platform for the creation and delivery of analytics, AI, and machine learning applications, among others.
Change Data Capture (CDC) helps your business stay competitive by keeping data up-to-date
Modern data and analytics leaders know that every business user is different. No two marketers or finance managers will use data in exactly the same way because no two share the same contextual view or understanding of the business. Their challenges are as nuanced as they are complex. And they need insights tailored to their specific needs if they are to be successful at solving business problems with data. Unfortunately, traditional BI tools treat everyone like carbon copies.
Last week in the BigQuery reference guide, we walked through query execution and how to leverage the query plan. This week, we’re going a bit deeper - covering more advanced queries and tactical optimization techniques. Here, we’ll walk through some query concepts and describe techniques for optimizing related SQL.
We are proud to announce that Iguazio has been named a sample vendor in five 2021 Gartner Hype Cycles, including the Hype Cycle for Data Science and Machine Learning, the Hype Cycle for Artificial intelligence, Analytics and Business Intelligence, Infrastructure Strategies and Hybrid Infrastructure Services, alongside industry leaders such as Google, IBM and Microsoft (who are also close partners of ours).
In our previous blog, we talked about the four paths to Cloudera Data Platform. If you haven’t read that yet, we invite you to take a moment and run through the scenarios in that blog. The four strategies will be relevant throughout the rest of this discussion. Today, we’ll discuss an example of how you might make this decision for a cluster using a “round of elimination” process based on our decision workflow.
“40% of all enterprise workloads will be deployed in CIPS [cloud infrastructure and platform services] by 2023, up from only 20% in 2020.”.As the cloud permeates every aspect of business, decision-makers must make critical choices regarding infrastructure at every turn. Their answers will ultimately determine if every part of an organization is empowered to move forward in a cohesive way to reach business outcomes.
Joint customers can now stay within AWS for all cloud services and minimize data movement costs.
Customers wanting to drive self-service analytics as part of creating a data-driven organization will often ask, “Can we achieve self service analytics, when our work force has low data literacy?” Or they might say they are not ready for self-service analytics, incorrectly thinking they need first to improve data literacy. But the two are inextricably linked. I liken it to teaching a child to read without giving them any books on which to build their skills.
With hackers now working overtime to expose business data or implant ransomware processes, data security is largely IT managers’ top priority. And if data security tops IT concerns, data governance should be their second priority. Not only is it critical to protect data, but data governance is also the foundation for data-driven businesses and maximizing value from data analytics. Requirements, however, have changed significantly in recent years.
Historically, maintenance has been driven by a preventative schedule. Today, preventative maintenance, where actions are performed regardless of actual condition, is giving way to Predictive, or Condition-Based, maintenance, where actions are based on actual, real-time insights into operating conditions. While both are far superior to traditional Corrective maintenance (action only after a piece of equipment fails), Predictive is by far the most effective.
In traditional data warehouses, specific types of data are stored using a predefined database structure. Due to this “schema on write” approach, prior to all data sources being consolidated into one warehouse, there needs to be a significant transformation effort. From there, data lakes emerge!
Over the past two decades, marketers have faced an uphill battle in trying to turn marketing into a fully data-driven discipline. Our challenge is not that we don’t have enough data but that data has been difficult to access and use. Marketing, sales, and product data is scattered across different systems, and we can’t get a complete picture of what is going on in our businesses.
Business intelligence (BI) is the art of extracting actionable insights from your datasets. There’s a whole stack of technologies under the hood.
Every day, hundreds of thousands of residents and commuters in San Francisco, California, use the public transportation services of the San Francisco Municipal Transportation Agency (SFMTA). In addition to the city’s buses, subway system, and famous cable cars, the SFMTA manages comprehensive services including bicycle and e-scooter rentals, as well as permits for road closures.
January 2020 is a distant memory, but for most, the early days of the pandemic was a time that will be ingrained in memories for decades, if not generations. Over the last 18 months, supply chain issues have dominated our nightly news, social feeds and family conversations at the dinner table. Some but not all have stemmed from the pandemic.
The global pandemic has changed B2C markets in many ways. In the U.S. market alone in 2020, consumers spent more than $860 billion with online retailers, driving up sales by 44% over the previous year.eCommerce sales are likely to remain high long after the pandemic subsides, as people have grown accustomed to the convenience of ordering online and having their goods – even groceries – delivered to their door.
Recently, I worked with a large fortune 500 customer on their migration from Apache Storm to Apache NiFi. If you’re asking yourself, “Isn’t Storm for complex event processing and NiFi for simple event processing?”, you’re correct. A few customers chose a complex event engine like Apache Storm for their simple event processing, even when Apache NiFi is the more practical choice, cutting drastically down on SDLC (software development lifecycle) time.
Earlier this year at Snowflake Summit 2021 , we announced Snowpark Accelerated , a new program for partners who integrate with Snowpark. It provides them with access to technical experts and additional exposure to Snowflake customers. It’s been incredibly exciting to watch what our partners have been building with the help of our new developer experience, which brings deeply integrated, DataFrame-style programming to the languages developers like to use.
The story of the last year+ is one of disruption and change across every aspect of our lives. As we all navigated a ‘new norm,’ businesses naturally had to pivot as well, with some sectors finding new opportunities while others scrambled to reimagine their entire go-to-market strategies.
What can we say: Research is non-linear, there are tests, and adjustments, and more tests, and more adjustments, and then we add more data, and test some more, and… you know the story.