Kimball vs Inmon: Which approach should you choose when designing your data warehouse architecture?
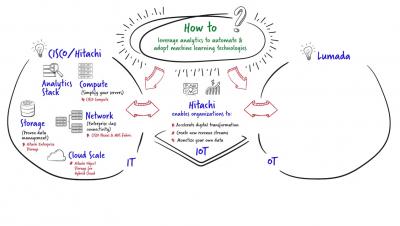
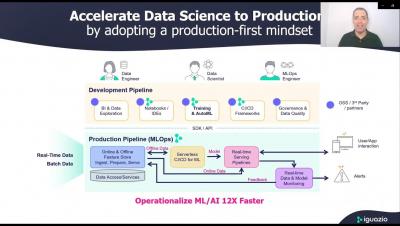
Data warehouses are the central data repository that allows Enterprises to consolidate data, automate data operations, and use the central repository to support all reporting, business intelligence (BI), analytics, and decision-making throughout the enterprise. But designing a data warehouse architecture can be quite challenging.