Best PPC Tools to Increase Your Ad Presence in 2022
From Google Keyword Planner to Spyfu and SEMrush, nearly 50 PPC professionals share how they are using their favorite PPC tools.


Startups and limited liability companies are known for their limited funds, and they prefer to cut down on employee payments to preserve money and recycle whatever they generate into their growth. As a result, they often offer equity compensation to their employees; more specifically, profits interests.
Financial professionals in real estate contend with a wide array of responsibilities—managing financial statements, office space floors, signage, storage space, land, and more. Regulations and interest rates are in a state of constant flux, and they must be assessed as changes arise to build accurate reports.
Eighty-nine percent of financial professionals across multiple geographies and industries are dissatisfied with their operational reporting tools. Why is that number so high? What are the challenges they’re facing? More importantly, what would it take to turn that dissatisfaction into satisfaction?
ThoughtSpot Everywhere provides SDKs to make embedding ThoughtSpot into your application easy. In addition to the more general JavaScript components for embedding ThoughtSpot, developers can also use React-specific components for those writing React applications. Using the React components you can quickly embed analytics with just a few lines of code.
Data may be everywhere, but it isn’t free. It takes a lot of work and infrastructure to turn raw data into useful insights. Research suggests that the cost of handling data is only going to increase, by as much as 50% over five years. The same source suggests that part of that cost comes from confusion — users may spend up to 40% of their time searching for data and up to 30% of their time on data cleansing. The issue here is data trust.
Has your company faced a ransomware attack yet? If not, count yourself lucky, for now. A June 2021 article in Cybersecurity Ventures predicts that ransomware will cost its victims approximately $265 billion annually by 2031. And, according to CRN, “Victims of the 10 biggest cyber and ransomware attacks of 2021 were hit with ransom demands totaling nearly $320 million.”
We all know the world is changing in profound ways. In the last few years, we’ve seen businesses, teams, and people all adapting — showing incredible resilience to keep moving forward despite the headwinds. To shed some light on what to expect in 2022 and beyond, let’s look at five major trends with regard to data. We’ve been watching these particular data trends since before the pandemic and seen them gain steam across sectors in the post-pandemic world.
It feels like a holy war is brewing in data management. At the heart of these rumblings is something that may seem sacrilege to many data architects: the days of the traditional data warehouse are numbered. For good reason. As data volumes continue to grow exponentially, the industry is united in recognizing we need a faster, more agile way to leverage data to unearth insights and drive actions. But that’s about all the industry agrees on.
When you take your car in for a repair, it’s almost inevitable that the mechanic will identify additional problems you didn’t realize you had. But there’s positive flip side to that coin — sometimes when you solve one problem, you end up unexpectedly creating solutions for other challenges—that was the case for this global automotive supplier. In 2019, this automotive supplier set a goal and created a roadmap to integrate its master data.
Sometimes it can feel like you’re stranded on a data island, scratching “SOS” in the sand in hopes of catching the eye of anyone who can rescue you. Companies everywhere are facing an explosion of data — with more data sources, more shadow IT, more people demanding access, and a growing number of business problems that can only be solved with data. As your company’s data leader, every one of those problems lands on you.
In the latest installment of the EMEA Influential Women in Data webinar series, we welcomed Shirley Collie, Chief Health Analytics Actuary at Discovery Health to discuss everything from how the pandemic has impacted working, to the opportunities within data, and the importance of intentionality.
Do you want to Install MongoDB on Ubuntu? Are you struggling to find an in-depth guide to help you set up your MongoDB database on your Ubuntu installation? If yes, then you’ve landed at the right place! Follow our easy step-by-step to seamlessly install and set your MongoDB database on any Ubuntu and Linux-powered system! This blog aims at making the installation process as smooth as possible!
Learn how data consultancy Untitled Firm effortlessly connects to its customer data and creates powerful analytic applications – using Powered by Fivetran.
Nearly one in three financial reports are manually produced Many decision-makers spend hours on recurring reports, which creates inefficiencies and costs companies tens of thousands per team member RALEIGH, N.C. – February 23, 2022 – insightsoftware, a global provider of financial reporting and performance management solutions for the Office of the CFO, today announced The Operational Reporting Global Trends Report.
A capitalization table, more commonly referred to as a “cap table,” provides a detailed record of the ownership stakes held by various investors, employees, and others who own shares in your company. The cap table documents who owns what, when it was acquired, what conditions may apply to ownership of specific shares, and more.
The telecommunications industry has been doing well since the pandemic started (not that many would notice). Revenues have remained relatively stable, while consumption has gone up, as virtual engagement has become the primary mode of operations for many businesses (and families!) In the mean-time, digital transformation has been accelerating both as a means to respond to the pandemic, and as a mechanism to drive costs down further, allowing for margin growth.
For almost a decade now, global business leaders have heralded the beginning of the Fourth Industrial Revolution, which refers to how technologies like AI, robotics, IoT, autonomous vehicles and computer vision are blurring the lines between the physical, digital, and biological spheres. Industry 4.0 has paved the way for transformative changes in business, unleashing advances in business process automation in the front and back office, driving unprecedented productivity and growth.
The road to the data-driven enterprise is not for the faint of heart. The continuous waves of data pounding into ever-complex hybrid multicloud environments only compound the ongoing challenges of management, governance, security, skills, and rising costs, to name a few. But Hitachi Vantara has developed a path forward that combines cloud-ready infrastructure, cloud consulting and managed services to optimize applications for resiliency and performance, and automated dataops innovations.
Organizations today face challenges from rapidly changing markets, new technologies, and the need to build new modern apps running in a multicloud environment. For this reason, business leaders are demanding faster delivery of new applications, services, and insight, requiring greater agility and efficiency from IT. Enterprises, rightly so, are investing in modernizing their on-premises infrastructure with increased use of the cloud.
Although many enterprises are at varying stages in their cloud journeys, most are adopting distributed mixes of on-premises and public cloud environments in order to maintain certain data and applications close by, while making others more accessible and available online. With such distributed cloud networks, core tenants of the enterprise, such as management, scalability and security, become increasingly challenging. There is a path forward, however.
We are happy to announce our latest addition of out-of-the-box analytics support for software lifecycle DevOps tools: Welcome to the Humanitec Insights connector! Humanitec is the Internal Developer Platform (IDP) that does the heavy lifting of Role-based access control (RBAC), Infrastructure Orchestration, Configuration Management and more. Humanitec’s API platform enables everyone to self-serve infrastructure and operate apps independently.
Operationalizing AI pipelines is notoriously complex. For deep learning applications, the challenge is even greater, due to the complexities of the types of data involved. Without a holistic view of the pipeline, operationalization can take months, and will require many data science and engineering resources. In this blog post, I'll show you how to move deep learning pipelines from the research environment to production, with minimal effort and without a single line of code.
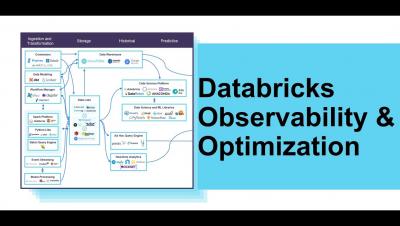
Over the past decade, the successful deployment of large scale data platforms at our customers has acted as a big data flywheel driving demand to bring in even more data, apply more sophisticated analytics, and on-board many new data practitioners from business analysts to data scientists. This unprecedented level of big data workloads hasn’t come without its fair share of challenges.
Organizations trust Snowflake with their sensitive data, such as their customers’ personal information. Ensuring that this information is governed properly is critical. First, organizations must know what data they have, where it is, and who has access to it. Data classification helps organizations solve this challenge.
Today’s applications run on data. Customers value applications not only for the functionality they provide, but also for the data itself. It may sound obvious, but without data, apps would provide little to no value for customers. And the data contained in these applications can often provide value beyond what the app itself delivers. This begs the question: Could your customers be getting more value out of your application data?
BigQuery is a serverless, highly scalable, and cost-effective data warehouse that customers love. Similarly, Dataflow is a serverless, horizontally and vertically scaling platform for large scale data processing. Many users use both these products in conjunction to get timely analytics from the immense volume of data a modern enterprise generates.
Cap tables are a valuable tool for a close look at the equity capitalization within your organization. But relying on static spreadsheets makes it difficult to gain a comprehensive, real-time view of your capitalization structure. Sifting through spreadsheets manually and reconciling disconnected systems are both time-consuming and cumbersome.
CDP Private Cloud Base is an on-premises version of Cloudera Data Platform (CDP). This new product combines the best of Cloudera Enterprise Data Hub and Hortonworks Data Platform Enterprise along with new features and enhancements across the stack. This unified distribution is a scalable and customizable platform where you can securely run many types of workloads. CDP is an easy, fast, and secure enterprise analytics and management platform with the following capabilities.
We recently wrote about the interest we’re seeing in connected applications that are built on Snowflake. Connected applications separate code and data such that the app provider creates and maintains the application code, while their customers manage their own data and provide their data platform for processing the application’s data. Some of our partners choose the connected application model because it has benefits for both customers and application providers.
Following the recent GA of Snowpark for our customers on AWS, we’re happy to announce that Snowpark Scala stored procedures are now available in preview to all customers on all clouds. Snowpark provides a language-integrated way to build and run data pipelines using powerful abstractions like DataFrames. With Snowpark, you write a client-side program to describe the pipeline you want to run, and all of the heavy lifting is pushed right into Snowflake’s elastic compute engine.
This post is going to be a bit of a step back into the past. As Mork from Ork would say: “nanu nanu.”
Here’s one of the most memorable quotes I have heard from a customer here in Asia: “Every time they tell me it’s ‘not in the universe’, I feel like mine is collapsing.”
Fully managed ELT, DataOps and more trends that will change the way we use data this year.
Kafka is a ubiquitous component of a modern data platform. It has acted as the buffer, landing zone, and pipeline to integrate your data to drive analytics, or maybe surface after a few hops to a business service. More recently, though, it has become the backbone for new digital services with consumer-facing applications that process live off the stream. As such, Kafka is being adopted by dozens, (if not hundreds) of software and data engineering teams in your organization.
Analysis-ready data models are built using sequences of transformations. Here's an example using Fivetran’s data model for Salesforce.
Digital technology promises transformative results. Yet, it’s not uncommon to encounter potholes and speed bumps along the way. One area that frequently trips up businesses is putting data into action. It can be extraordinarily difficult to take advantage of the right data at exactly the right time — in real time — to drive decision-making. For SAP customers wanting to maximize the value of their data, Google Cloud offers a number of capabilities.
The value of healthy data is obvious. But how do you build that practice in your own business? The difference between people who live a healthy lifestyle and those who don’t isn’t whether they know how to be healthier — it’s whether or not they prioritize diet, sleep, and exercise in their daily life. The same is true for your data: if you don’t have the infrastructure that supports your customer 360 initiatives , those initiatives become moot.
While it is a little dated, one amusing example that has been the source of countless internet memes is the famous, “is this a chihuahua or a muffin?” classification problem. Figure 01: Is this a chihuahua or a muffin? In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin.
The time has come for the open-source software revolution to reach SQL.
During a Teradata migration to BigQuery, one complex and time consuming process is migrating Teradata users and their permissions to the respective ones in GCP. This mapping process requires admin and security teams to manually analyze, compare, and match hundreds to thousands of Teradata user permissions to BigQuery IAM permissions. We already described this manual process for some common data access patterns in our earlier blog post.
Budgeting is one of those essential processes in which every business must engage. It’s critical to have a meaningful financial plan in place, to have realistic targets to achieve. Unfortunately, traditional models for financial planning and budgeting are increasingly strained as businesses strive to cope with change. Many are seeking leaner, more agile budgeting and planning options.
It’s official — Self-Service Data APIs are available as a new feature of Data Inventory! Highly skilled and less-technical users can now make their datasets available to applications and partners via APIs in just a few clicks. Self-Service Data APIs empower every permissioned employee to leverage data across the business to generate valuable insights or even extend data availability beyond the organization to trusted partners.
Piano is a leading provider of software and services that help organizations better understand their audiences across digital channels. With these insights in hand, Piano customers can intelligently serve audiences with personalized experiences that keep them engaged and drive revenue, all through a single unified platform.
Almost every organization is a data organization. Yet, as data proliferates, data ecosystems have become increasingly complex, making it harder for organizations to control and prevent data quality issues from occurring. Data Observability gives organizations the ability to monitor data usage throughout the data ecosystem.
Being data-driven is no longer optional. With increased digital dexterity among customers and fast-changing market conditions and disruptions, organizations have entered the defining decade of data. This new era is characterized in part by the need to put live data directly into the hands of frontline decision-makers with self-service analytics.
Learn the 6 steps to easily and securely onboard data from your customers, without ever touching their login credentials. It’s as easy as sending an email.
Thirty five years ago, SQL-86, the first SQL standard, came into our world, published as an ANSI standard in 1986 and adopted by the International Standards Organization (ISO) in 1987. On this Valentine’s Day, we, in BigQuery, reaffirm our love and commitment to user-friendly SQL through a whole slew of new SQL features that we’re pleased to share with you, our beloved BigQuery users.
Finance teams have played a leading role in the adoption of technology to transform previously inefficient manual or spreadsheet-based processes. While investment in tax and transfer software has tended to lag that in core finance systems, adoption is maturing and pressure from the office of the CFO to implement digital tools is beginning to grow.
Note: This is part 2 of the Make the Leap New Year’s Resolution series. For part 1 please go here. When we introduced Cloudera Data Engineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale.
In recent years, Ethical AI has become an area of increased importance to organisations. Advances in the development and application of Machine Learning (ML) and Deep Learning (DL) algorithms, require greater care to ensure that the ethics embedded in previous rule-based systems are not lost. This has led to Ethical AI being an increasingly popular search term and the subject of many industry analyst reports and papers.
During the information age, and throughout the 4th industrial revolution, technology, data and information were in abundance. But, soon came the realization that technology and access to all of the data and information, by itself, was not the solution.
It’s no secret that it’s much cheaper to retain a customer than get a new one — 5 times cheaper, according to Forbes. The paradigm however seems to be changing: retaining is not enough when there are a lot of easily reachable competitors out there. You need to go one step further: make customers loyal.
As a modern, data-driven organization, you are likely pulling data from a multitude of diverse sources. There’s consumer data from marketing programs, CRM, and point of sale systems, plus financial data from accounting software and banking services. Finally, there is product data from user logs and web applications. With so much data pouring in every day, it feels like you should have everything you need to answer any question that could arise. And yet, so many times you don’t.
After the launch of Cloudera DataFlow for the Public Cloud (CDF-PC) on AWS a few months ago, we are thrilled to announce that CDF-PC is now generally available on Microsoft Azure, allowing NiFi users on Azure to run their data flows in a cloud-native runtime. With CDF-PC, NiFi users can import their existing data flows into a central catalog from where they can be deployed to a Kubernetes based runtime through a simple flow deployment wizard or with a single CLI command.
Electricity is fundamental to our society. As climate change becomes more severe and demand for clean energy increases, the future is the electrification of everything and along with it, the need for reliable energy. The U.S. infrastructure spans over a vast 200,000 miles and inspecting all of it is a time-consuming and high-risk process that often calls for hanging from helicopters or climbing tall towers. It is inefficient, costly, and dangerous.
Data marts are miniature, specialized data warehouses.
Are you storing your data in BigQuery and interested in using that data to train and deploy models? Or maybe you’re already building ML workflows in Vertex AI, but looking to do more complex analysis of your model’s predictions? In this post, we’ll show you five integrations between Vertex AI and BigQuery, so you can store and ingest your data; build, train and deploy your ML models; and manage models at scale with built-in MLOps, all within one platform. Let’s get started!
At Wayfair, we have several unique challenges relating to the scale of our product catalog, our global delivery network, and our position in a multi-sided marketplace that supports both our customers and suppliers. To give you a sense of our scale we have a team of more than 3,000 engineers with tens of millions of customers. We supply more than 20 Million items using more than 16,000 supplier partners.
2021 Technology Innovation Awards recognize top performers in Wisdom of Crowds® Thematic Market Studies Raleigh, N.C., February 9, 2022 – Logi Analytics, an insightsoftware company, today announced it has been named a winner for Embedded Business Intelligence (BI) in the 2021 Technology Innovation Awards by Dresner Advisory Services.
Heading into a new year filled with myriad crosscurrents, this much is certain: more organizations will find smarter ways to use data as they realize the benefits of digitally transforming their operations. We’re seeing this trend toward data-driven decision making already play out in different industries around the world as companies modernize their infrastructures.
Microsoft customers can discover, transact and deploy Fivetran’s fully managed and automated data pipelines in Azure and more.
In this article, we’ll take a deep dive into the customer churn/retention use case. This should contain everything needed to get started on the use case, and enterprising readers can also try this out for themselves in a free trial of Continual, following the customer churn example in the linked github repository.
Cloudera has been recognized as a Visionary in 2021 Gartner® Magic Quadrant™ for Cloud Database Management Systems (DBMS) and for the first time, evaluated CDP Operational Database (COD) against the 12 critical capabilities for Operational Databases.
2021 demonstrated the precariousness of our global supply chains and the potential cost to business. The Suez Canal blockage held up around $9.6bn of trade each day, while the true impact of the pandemic won’t be known for years. Many of us have also felt it during our weekly shopping and the disappointment when one of our favorite items is replaced by cardboard cutouts instead of the foodstuff themselves.
Having a firm understanding of Google BigQuery Data types is necessary if you are to take full advantage of the warehousing tool’s on-demand offerings and capabilities. We at Hevo Data (Hevo is a unified data integration platform that helps customers bring data from 100s of sources to Google BigQuery in real-time without writing any code) often come across customers who are in the process of setting up their BigQuery Warehouse for analytics.
Here’s a scenario that might feel painfully familiar. Your marketing department captures customer leads, and passes them to the sales department. Marketing’s success is measured in part on the number and size of deals that result. But a squabble breaks out over how the sales department handles, nurtures, and attributes those conversions. Result: Neither department really wants to share their data.
Apache Kafka is a distributed message broker designed to handle large volumes of real-time data efficiently. Unlike traditional brokers like ActiveMQ and RabbitMQ, Kafka runs as a cluster of one or more servers which makes it highly scalable and due to this distributed nature it has inbuilt fault-tolerance while delivering higher throughput when compared to its counterparts. This article will walk you through the steps to install Kafka on Ubuntu 20.04 using simple 8 steps.
Data lakes serve as central destinations for business data and offer users a platform to guide business decisions.
For small entrepreneurial businesses, equity compensation can be a very attractive way to attract and retain highly talented employees. In a nutshell, equity compensation is defined as non-cash remuneration that takes the form of stock options, restricted shares, employee stock purchase plans, and other vehicles that provide employees with an equity stake in the company. Equity compensation may also apply to non-employee services provided by independent contractors, board members, or advisors.
This blog post provides an overview of the HBase to CDP Operational Database (COD) migration process. CDP Operational Database enables developers to quickly build future-proof applications that are architected to handle data evolution. It helps developers automate and simplify database management with capabilities like auto-scale and is fully integrated with Cloudera Data Platform (CDP).
Sometimes the lifestyles of the rich and famous aren’t as glamorous as they seem at first glance. We all know that professional athletes can make incredible amounts of money. But by the age of 35, most pro athletes are already at the end of their prime earning years. Historically, a lot of them haven’t managed their money well — and they may even go bankrupt in retirement.
Learn why data transformation is essential to data modeling and bringing your organization to the forefront of data literacy.
Is your model ready for production? It depends on how it’s measured. And measuring it with the right metric can unlock even better performance. Evaluating model performance is a vital step in building effective machine learning models. As you get started on Continual and start building models, understanding evaluation metrics helps to productionize the best performing model for your use case.
We often hear different terms used to describe forward-looking versions of a company’s financial statements. People frequently use these terms interchangeably, with some having a deeper understanding of the nuances in terminology than others. Forward-looking financial documents may include budgets, projections, forecasts, and pro forma financials.
Last time in this blog series, we provided an overview of how to leverage the Iguazio Feature Store with Azure ML in part 1. We built out a training workflow that leveraged Iguazio and Azure, trained several models via Azure's AutoML using the data from Iguazio's feature store in part 2. Finally, we downloaded the best models back to Iguazio and logged them using the experiment tracking hooks in part 3. In this final blog, we will.
In the past, data leaders had to manage a balancing act between data access and governance. Granting too much access meant opening up the business—and the privacy of consumers—to risk. But if you hold back data, you can’t deliver great experiences and value to customers. The Snowflake Media Data Cloud empowers companies to let go of the balancing act. They now have a single platform to store, govern, and share data while maintaining strict data governance.
We recently sat down with Sandeep Uttamchandani, Chief Product Officer at Unravel, to discuss the top cloud data migration challenges in 2022. No question, the pace of data pipelines moving to the cloud is accelerating. But as we see more enterprises moving to the cloud, we also hear more stories about how migrations went off the rails. One report says that 90% of CIOs experience failure or disruption of data migration projects due to the complexity of moving from on-prem to the cloud. Here are Dr.
Unlimited resyncs, moving from credits to dollars, new pricing plan, and more.
Flow Engineering is the science of creating, visualizing and optimizing the flow of value from your company to the customers. In the end that is the million-dollar (likely more) challenge of most product companies: How to we create value in the form of product and services and ship those to our customers as quickly, sustainably and frictionless as possible.
Okay, I admit, the title is a little click-batey, but it does hold some truth! I spent the holidays up in the mountains, and if you live in the northern hemisphere like me, you know that means that I spent the holidays either celebrating or cursing the snow. When I was a kid, during this time of year we would always do an art project making snowflakes. We would bust out the scissors, glue, paper, string, and glitter, and go to work.
More than a decade into the Internet of Things (IoT) era, the immense potential of IoT is becoming real. We’re moving from proof of concepts and pilots to projects at scale. What’s become increasingly clear is the vast complexity of deploying IoT solutions at scale and the necessity to do so to become a data-driven business.
Disclaimer: This post is a preview of the O'Reilly Report. If you wish to directly download it, click here -