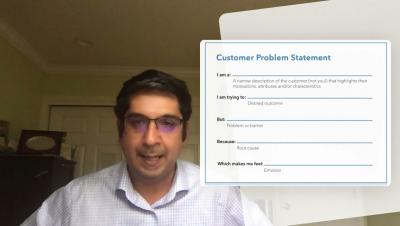
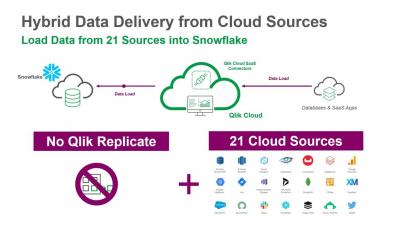
How Embedded Analytics Creates A Data-Driven Culture
A lack of understanding regarding the role of data in decision-making is a reoccurring challenge for many organizations. However, with the increase in quantity and complexity of data, you need to do everything possible to help your people use data effectively.