Troubleshoot and optimize your BigQuery analytics queries with query execution graph
The query execution graph provides performance insights to help you easily understand, troubleshoot and optimize your BigQuery analytics queries.


The query execution graph provides performance insights to help you easily understand, troubleshoot and optimize your BigQuery analytics queries.
Ever dealt with a misbehaving consumer group? Imbalanced broker load? This could be due to your consumer group and partitioning strategy! Once, on a dark and stormy night, I set myself up for this error. I was creating an application to demonstrate how you can use Apache Kafka® to decouple microservices. The function of my “microservices” was to create latte objects for a restaurant ordering service.
BigQuery query queues introduces a dynamic concurrency limit and enables queueing based on available slot capacity and how many queries are running.
Have you heard the phrase “AI won't replace humans - but humans with AI will replace humans without AI”? I personally love this quote because it perfectly encapsulates the nature of the anticipated workforce shift from the rise of generative AI. As I wrote back in 2017, the power of AI is not about machines supplanting human abilities, but rather about a symbiotic relationship between humans and AI. I think the Star Trek analogy I used then is standing the test of time…
A new cross-cloud join feature in BigQuery Omni lets users to query data across clouds in a single SQL statement.
As data ecosystems evolve security becomes a paramount concern, especially within the realm of private cloud environments. Cloudera on Private Cloud with the Private Cloud Base (CDP PvC Base) stands as a beacon of innovation in the realm of data security, offering a holistic suite of features that work in concert to safeguard sensitive information.
At Snowflake, we are dedicated to helping our customers effectively mobilize their data while upholding stringent standards for compliance and data governance. We understand the importance of quick and proactive identification of objects requiring governance, as well as the implementation of protective measures using tags and policies.
Organizations increasingly rely on streaming data sources not only to bring data into the enterprise but also to perform streaming analytics that accelerate the process of being able to get value from the data early in its lifecycle. As lakehouse architectures (including offerings from Cloudera and IBM) become the norm for data processing and building AI applications, a robust streaming service becomes a critical building block for modern data architectures.
In the first three parts of our Inside Flink blog series, we discussed the benefits of stream processing, explored why developers are choosing Apache Flink® for a variety of stream processing use cases, and took a deep dive into Flink's SQL API. In this post, we'll focus on how we’ve re-architected Flink as a cloud-native service on Confluent Cloud. However, before we get into the specifics, there is exciting news to share.
The Q3 Confluent Cloud Launch comes to you from Current 2023, where data streaming industry experts have come together to share insights into the future of data streaming and new areas of innovation. This year, we’re introducing Confluent Cloud’s fully managed service for Apache Flink®, improvements to Kora Engine, how AI and streaming work together, and much more.
Enterprises are drowning in data. Structured, semi-structured or unstructured data for the modern, data-driven enterprise is everything, everywhere, all at once. But that’s also a challenge for enterprises looking to transform their data into usable information for business success. The sheer volume of data is challenging the ability of enterprises to find trustworthy, reliable data to drive their business decisions. Traditional data catalogs offer only structured data discovery.
Not all heroes in the tech world write code. Some wield the power of data analytics and SEO to create compelling stories and foster brand growth. This week, our Monday Member Spotlight features Jose, TestQuality’s Marketing Assistant with years of specialized experience in Google Analytics and SEO. Let's explore how he takes a data-driven approach to spread the word about TestQuality.
Navigating the intricacies of Apache Kafka just got a lot more intuitive. With Lenses 5.3 we bring you peace of mind, regardless of where you are in your Kafka journey. Our newest release is all about smoothing out the bumps, and making sure you're equipped to handle Kafka's challenges with confidence. Here's a sprinkle of what's in store, ahead of our big 6.0 release later this year.
We like to reduce the most mundane, complex and time-consuming work associated with managing a Kafka platform. One such task is backing up topic data. With a growing reliance on Kafka for various workloads, having a solid backup strategy is not just a nice-to-have, but a necessity. If you haven’t backed up your Kafka and you live in fear of disaster striking, worry no more.
An effective data platform thrives on solid data integration, and for Kafka, S3 data flows are paramount. Data engineers often grapple with diverse data requests related to S3. Enter Lenses. By partnering with major enterprises, we've levelled up our S3 connector, making it the market's leading choice. We've also incorporated it into our Lenses 5.3 release, boosting Kafka topic backup/restore.
AtScale enables Google Cloud users to build a single source of governed analytics to enable self-service business intelligence and data science programs.
How Windsor.ai, a Google Cloud Ready - BigQuery partner, helped Anything is Possible to build an automated pipeline into BigQuery.
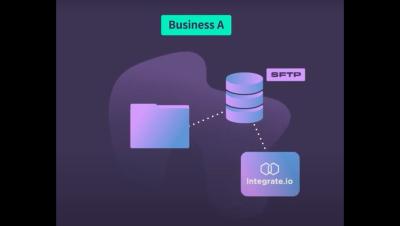
When transferring data, especially in the context of Extract, Transform, and Load (ETL), the choice of protocol matters. Both SFTP and FTP provide solutions, but their intrinsic differences could greatly influence the outcome in terms of security and functionality. Here's everything you need to know about SFTP vs. FTP for ETL.
With 11 new blockchains in the BigQuery public datasets program, the Web3 community gets a more comprehensive view of the crypto landscape.
Although it might seem a little early, I was just thinking: what will 2023 be remembered for? For many it will be the year that Beyonce and Taylor Swift took to stages around the world and pushed the boundaries of live music (I’m a confirmed Swiftie if you didn’t know). It is also the year of AI. When I speak with customers, they all talk about how they are steering towards AI adoption.
Bloomreach Engagement, an omnichannel marketing automation product, now integrates with BigQuery, providing hyper-personalized customer experiences.
Perhaps your C-suite is already a bit crowded. The typical hierarchy will include a CEO, COO, CFO, CTO, CMO, CIO, and a few more. Adding another position may not be terribly appealing, but there is one C-suite role every company should consider—chief data and analytics officer (CDO or CDAO).
By the end of this two-part series, we will dive into what data warehouse architecture is and how to implement one for your organization. Part one will look at architectural layers and common data warehouse components, while part two dives into multi-tiered data warehouse architecture.
Confluent and AWS Lambda can be used for building real-time, scalable, fault-tolerant event-driven architectures, ensuring that your application logic is executed reliably in response to specific business events. Confluent provides a streaming SaaS solution based on Apache Kafka® and built on Kora: The Cloud Native Apache Kafka Engine, allowing you to focus on building event-driven applications without operating the underlying infrastructure.
Unlock faster time to insights for your transactional and analytical use cases today.
One of my favorite analogies is that data is the lifeblood of the business. Before you roll your eyes at me (I see it now), hear me out. At your annual physical, when you get your blood work done, think of how much information is uncovered about your overall health from a tiny vial of your blood. From those 10 CCs they extract comes back pages of information regarding your cell counts, glucose, cholesterol, and other information.
Apache Kafka® supports incredibly high throughput. It’s been known for feats like supporting 20 million orders per hour to get COVID tests out to US citizens during the pandemic. Kafka's approach to partitioning topics helps achieve this level of scalability. Topic partitions are the main "unit of parallelism" in Kafka. What’s a unit of parallelism? It’s like having multiple cashiers in the same store instead of one.
Generative AI is a powerful tool for accelerating the branding process for new products or compounds.
As customers scale data warehousing in the cloud with BigQuery, cost optimization becomes crucial for scalable data storage in the cloud.
BigQuery’s new SQL capabilities deliver improved analytics flexibility, data quality and security.
The world is awash with data, no more so than in the telecommunications (telco) industry. With some Cloudera customers ingesting multiple petabytes of data every single day— that’s multiple thousands of terabytes!—there is the potential to understand, in great detail, how people, businesses, cities and ecosystems function.
In the age of the AI revolution, where chatbots, generative AI, and large language models (LLMs) are taking the business world by storm, enterprises are fast realizing the need for strong data control and privacy to protect their confidential and commercially sensitive data, while still providing access to this data for context-specific AI insights.
Data is essential to marketing. It’s how we know our audience and measure campaign outcomes. It shows us where to adjust a campaign on the fly, for even better results. But working with data is increasingly complex, and having the right stack of technologies is invaluable.
We’re thrilled to announce that both ThoughtSpot and Mode (acquired by ThoughtSpot in July 2023) have been recognized as Leaders in Snowflake's recent Modern Marketing Data Stack report! Given the ever-evolving landscape of modern data analytics products, organizations are looking to ThoughtSpot and Mode when seeking innovative solutions—helping them harness the power of their marketing data.
Based on the usage of thousands of Snowflake customers, leading marketers are leveraging Fivetran to tackle Customer 360.
With marketing analytics now influencing more than half (53%) of marketing decisions, there’s finally some good information around using data in marketing. In fact, Gartner found that when analytics influences less than 50% of decisions, organizations find it challenging to prove the value of their marketing.
With marketing analytics now influencing more than half (53%) of marketing decisions, there’s finally some good data around using data in marketing. In fact, Gartner found that when analytics influences less than 50% of decisions, organizations find it challenging to prove the value of their marketing.
Recently, I got my hands dirty working with Apache Flink®. The experience was a little overwhelming. I have spent years working with streaming technologies but Flink was new to me and the resources online were rarely what I needed. Thankfully, I had access to some of the best Flink experts in the business to provide me with first-class advice, but not everyone has access to an expert when they need one.
Traditional metrics like ticket resolution time or customer satisfaction scores (CSAT) are undeniably significant. However, to gain a more holistic picture, product analytics can be applied to:
Semantic layers are a game changer, allowing organizations to define metrics and business logic in one, centralized location. Because business users can trust that their data is built on a single source of truth, the semantic layer also empowers self-service analytics. Looker Modeler has become a leader among semantic layers, allowing users to seamlessly layer on top of their business data.
Automation, reliability and scale are the seeds for growing innovation.
Snowflake and Salesforce have built on our existing partnership to unify the full breadth of customer and business data and generate actionable insights for our customers. We are happy to announce the general availability of Bring Your Own Lake (BYOL) Data Sharing with the Snowflake Data Cloud from Salesforce Data Cloud. Organizations can now leverage Salesforce data directly in Snowflake via zero-ETL data sharing to accelerate decision-making and help streamline business processes.
ThoughtSpot users can easily create content with data using our intuitive, AI-powered search experience. However, business users sometimes find themselves asking a critical question: which content should I trust and use for my specific business use case? For example, if there are ten “Sales Performance” Liveboards created by different authors, you may wonder which is the golden version—the Liveboard that is reviewed, approved, and consistently maintained.
In the first two parts of our Inside Flink blog series, we explored the benefits of stream processing with Flink and common Flink use cases for which teams are choosing to leverage the popular framework to unlock the full potential of streaming. Specifically, we broke down the key reasons why developers are choosing Apache Flink® as their stream processing framework, as well as the ways in which they are putting it into practice.
One of the most important questions in architecting a data platform is where to store and archive data. In a blog series, we’ll cover the different storage strategies for Kafka and introduce you to Lenses’ S3 Connector for backup/restore. But in this first blog, we must introduce the different Cloud storage options available. Later blogs will focus on specific solutions, explain in more depth how this maps to Kafka and then how Lenses manage your Kafka topic backups.
CNA worked with Google Cloud and several third-party data vendors to develop a solution to address challenges with underwriting flood risk assessment.
Financial professionals encounter periods of high activity throughout the year. Whether you serve as a CFO, specialize in taxation, or contribute to the team responsible for closing financial records and generating year-end reports, any time can become crunch time. These intervals demand long hours at the office (or working evenings from your home office) as you diligently tackle the extensive list of tasks that require immediate attention.
With the emergence of new creative AI algorithms like large language models (LLM) fromOpenAI’s ChatGPT, Google’s Bard, Meta’s LLaMa, and Bloomberg’s BloombergGPT—awareness, interest and adoption of AI use cases across industries is at an all time high. But in highly regulated industries where these technologies may be prohibited, the focus is less on off the shelf generative AI, and more on the relationship between their data and how AI can transform their business.
In today’s high-velocity digital arena, businesses are thrust into the whirlwind of global events, rapid technological advancements, and the incessant push for innovation. Yet, amidst the tempest of mergers, digital acceleration, and shifting tech paradigms, charting a confident path towards cloud migration can be daunting.
Snowpark is the set of libraries and runtimes that enables data engineers, data scientists and developers to build data engineering pipelines, ML workflows, and data applications in Python, Java, and Scala. Functions or procedures written by users in these languages are executed inside of Snowpark’s secure sandbox environment, which runs on the warehouse.
Product analytics traditionally hinged on examining user interactions to extract actionable insights. The integration of machine learning (ML) has elevated this process, enriching our understanding and our ability to predict future trends. Let's unfold how ML integrates into product analytics and the transformative advantages it introduces.
Is Windows your favorite development environment? Do you want to run Apache Kafka® on Windows? Thanks to the Windows Subsystem for Linux 2 (WSL 2), now you can, and with fewer tears than in the past. Windows still isn’t the recommended platform for running Kafka with production workloads, but for trying out Kafka, it works just fine. Let’s take a look at how it’s done.
At Cloudera, we’re known for making innovative technological solutions that drive change and impact the world. Our mission is to make data and analytics easy and accessible to everyone. And that doesn’t end with our customer base. We also aim to provide equitable access to career opportunities within data and analytics to the workforce of tomorrow.
Learn the crucial role of data governance and security in database replication.
In a survey by the Harvard Business Review, 87% of respondents stated their organizations would be more successful if frontline workers were empowered to make important decisions in the moment. And 86% of respondents stated that they needed better technology to enable those in-the-moment decisions. Those coveted insights live at the end of a process lovingly known as the data pipeline.
Various factors can impede an organization's ability to leverage Confluent Cloud, ranging from data locality considerations to stringent internal prerequisites. For instance, specific mandates might dictate that data be confined within a customer's Virtual Private Cloud (VPC), or necessitate operation within an air-gapped VPC. However, a silver lining exists even in such circumstances, as viable alternatives remain available to address these specific scenarios.
Companies want to train and use large language models (LLMs) with their own proprietary data. Open source generative models such as Meta’s Llama 2 are pivotal in making that possible. The next hurdle is finding a platform to harness the power of LLMs. Snowflake lets you apply near-magical generative AI transformations to your data all in Python, with the protection of its out-of-the-box governance and security features.
Enterprises are leveraging cloud investments to supercharge marketing efforts by building a Composable CDP with BigQuery and Hightouch.