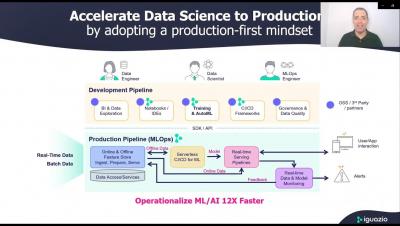
It Worked Fine in Jupyter. Now What?
You got through all the hurdles getting the data you need; you worked hard training that model, and you are confident it will work. You just need to run it with a more extensive data set, more memory and maybe GPUs. And then...well. Running your code at scale and in an environment other than yours can be a nightmare. You have probably experienced this or read about it in the ML community. How frustrating is that? All your hard work and nothing to show for it.