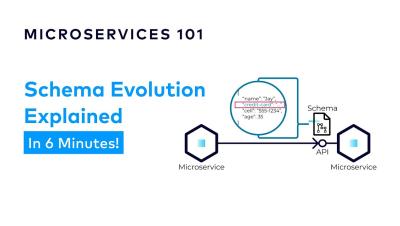
Confluent announces general availability of Confluent Cloud for Apache Flink®, simplifying stream processing to power next-gen apps
Confluent Cloud for Apache Flink®, a leading cloud-native, serverless Flink service is now available on AWS, Google Cloud, and Microsoft Azure. Confluent's fully managed, cloud-native service for Flink helps customers build high-quality data streams for data pipelines, real-time applications, and analytics.