

How to get Observability for Apache Airflow
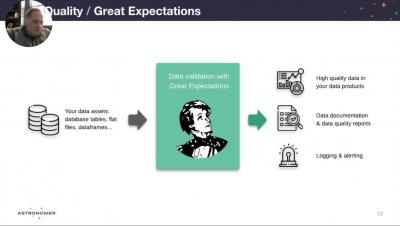
Observability of Apache Airflow presented by Ry Walker, Founder & CTO at Astronomer. Apache Airflow has become an important tool in the modern data stack. We will explore the current state of observability of Airflow, common pitfalls if you haven't planned for observability, and chart a course for where we can take it going forward.







