Elevating Data Science Practices for the Media, Entertainment & Advertising Industries
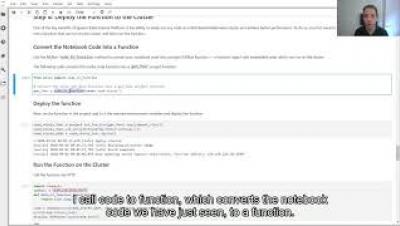
As more and more companies are embedding AI projects into their systems, attracted by the promise of efficiencies and competitive advantages, data science teams are feeling the growing pains of a relatively immature practice without widespread established and repeatable norms.