Automating MLOps for Deep Learning
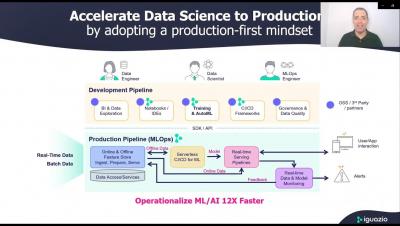
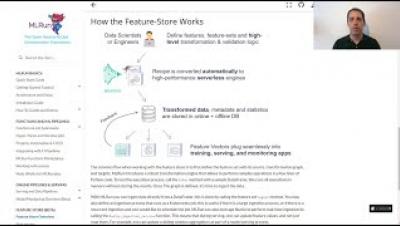
MLOps holds the key to accelerating the development, deployment and management of AI, so that enterprises can derive real business value from their AI initiatives. Deploying and managing deep learning models in production carries its own set of complexities. In this talk, we will discuss real-life examples from customers that have built MLOps pipelines for deep learning use cases. For example, predicting rainfall from CCTV footage to prevent flooding.