

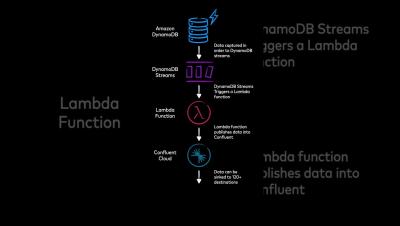
How to source data from AWS DynamoDB to Confluent using DynamoDB Streams and AWS Lambda
This is a one-minute video showing an animated architectural diagram of the integration between Amazon DynamoDB and Confluent Cloud using DynamoDB Streams and AWS Lambda. Details of the integration are provided via narration.








