MLOps Bay Area Summit: From AutoML to AutoMLOps
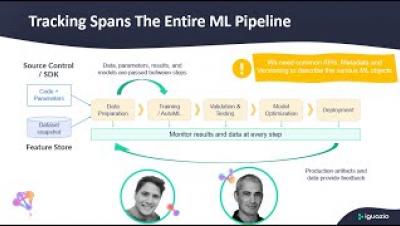
AutoMLOps means automating engineering tasks so that your code is automatically ready for production. In this session, Yaron outlined the challenges, describe open-source tools available for Auto-MLOps, and more!