Mailchimp
Not subscribed to OpsMatters Newsletter


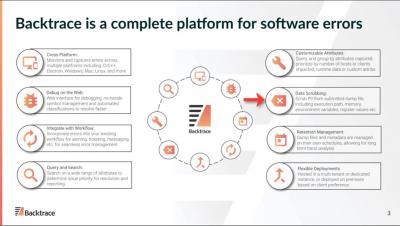
Testing any software project is an important step in order to find out how the software functions. Learning when the project acts as expected (and when it does not) is the ultimate goal of the testing process. Testing stops design errors from reaching production code. However, testing should not only happen before code is deployed.
In my previous blog posts, I’ve talked about how you can aggregate data depending on the data type, as well as how you can re-express your data to get more value from it. For this post, let’s look at some of the different ways of measuring your data.
Ask any analyst how they spend the majority of their work day and they’ll tell you: Performing remedial tasks that provide no analytics value. 92% of data workers report that their time is being siphoned away performing operational tasks outside of their roles. Data teams waste an inordinate amount of time maintaining the delicate data-to-dashboards pipelines they’ve created, leaving only 50% of their time to actually analyze data.
Think back to when your development team made the switch to Dockerized containers. What was once an application requiring multiple services on virtual machines transitioned to an application consisting of multiple, tidy Docker containers. While the result was a streamlined system, the transition likely was daunting. Now, it’s time for another transformational leap: moving from a single set of containers to a highly available, orchestrated deployment of replica sets using Kubernetes.