Transform your business with cloud, search, and AI-driven analytics
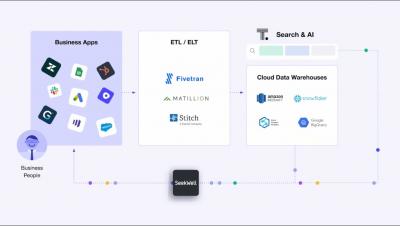
Despite huge investments in data and analytics over the last two decades, many companies are still struggling with how to become truly data-driven. What are data leaders doing at the organizations that have figured it out? In this white paper, DATAcated Academy's Kate Strachnyi explores four key strategies for critically evaluating your entire data and analytics stack and systematically removing the barriers that exist between their business users and business-critical insights.