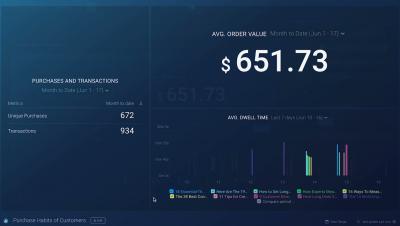
What to Measure?
In my previous blog posts, I’ve talked about how you can aggregate data depending on the data type, as well as how you can re-express your data to get more value from it. For this post, let’s look at some of the different ways of measuring your data.